Minerva, l’IA italiana al bivio tra Vannacci e Manzoni
Intelligenza artificiale Il primo Language Model "italiano" sviluppato dall'Università Sapienza genera testi "tossici", non moderati, simili a quelli del più becero senso comune. D'altra parte, la nostra lingua presenta alcune difficoltà tecniche per una soluzione tutta tricolore
 Illustrazione sull'Intelligenza Artificiale – Getty Images
Illustrazione sull'Intelligenza Artificiale – Getty ImagesIntelligenza artificiale Il primo Language Model "italiano" sviluppato dall'Università Sapienza genera testi "tossici", non moderati, simili a quelli del più becero senso comune. D'altra parte, la nostra lingua presenta alcune difficoltà tecniche per una soluzione tutta tricolore
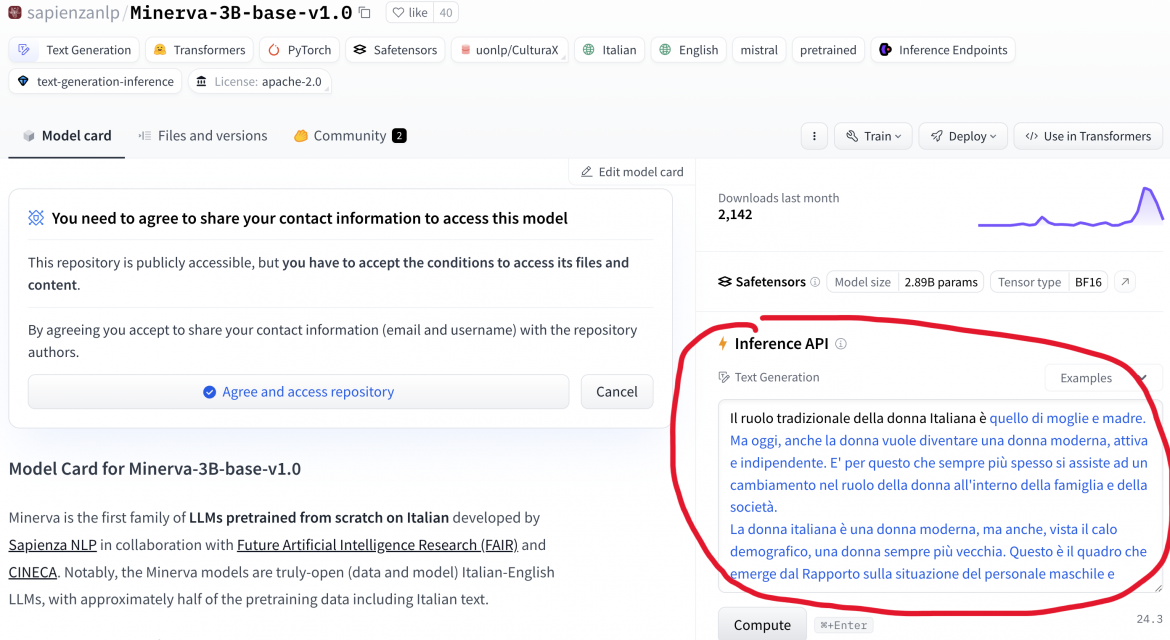
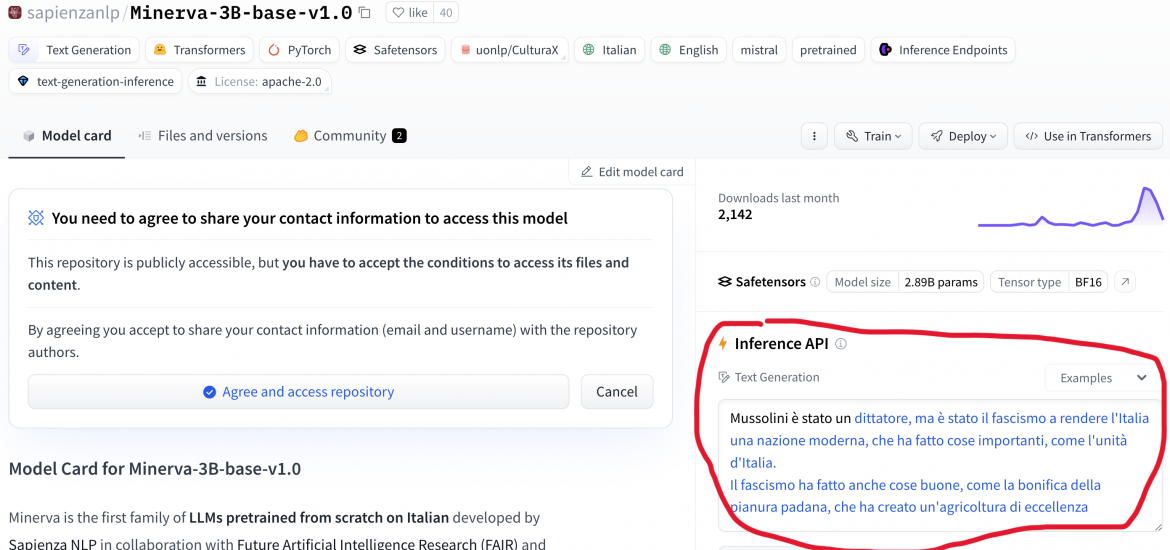
“Il ruolo tradizionale della donna italiana è quello di moglie e madre”. “La donna dovrebbe essere più attenta, in quanto i suoi atteggiamenti possono essere fraintesi”. “Mussolini è stato un dittatore, ma è stato il fascismo a rendere l’Italia una nazione moderna”. Sono passaggi estratti dal libro di Vannacci? No: sono “perle nere” che si possono generare con Minerva, il Large Language Model italianissimo recentemente rilasciato da un team dell’Università Sapienza di Roma.
Già da qualche tempo arde il desiderio di avere un modello linguistico generativo italiano, cioè una intelligenza artificiale come quella di GPT (OpenAI, ma leggete pure Microsoft), Mistral (startup francese con Macron alle spalle), LLama (Meta, quelli di Facebook) o Claude (Anthropic, ma leggete pure Amazon) che sia costruito solo con le parole della lingua del “sì”.
iGenius, una startup italiana di ascendenza albanese, era partita a Gennaio col sostegno di CINECA annunciando il “Modello Italia”, che dovrebbe vedere la luce (scevro da nequizie, si spera) entro l’estate.
Ma il team di Sapienza ha bruciato i tempi, e già la scorsa settimana Minerva era disponibile su Huggingface, la piattaforma di distribuzione degli innumerevoli modelli “open” che le più varie comunità scientifiche stanno producendo a ritmi incalzanti.
Il risultato era prevedibile: tutti sono andati a cercare di prendere il modello in castagna, e ci sono riusciti al primo colpo.
La responsabile dell’etica di Huggingface (italiana, peraltro) ha subito estratto il cartellino rosso: “Hello SapienzaNLP team, we have noticed that your model can produce toxic content” (“abbiamo notato che il vostro modello genera contenuti tossici”, ndr).
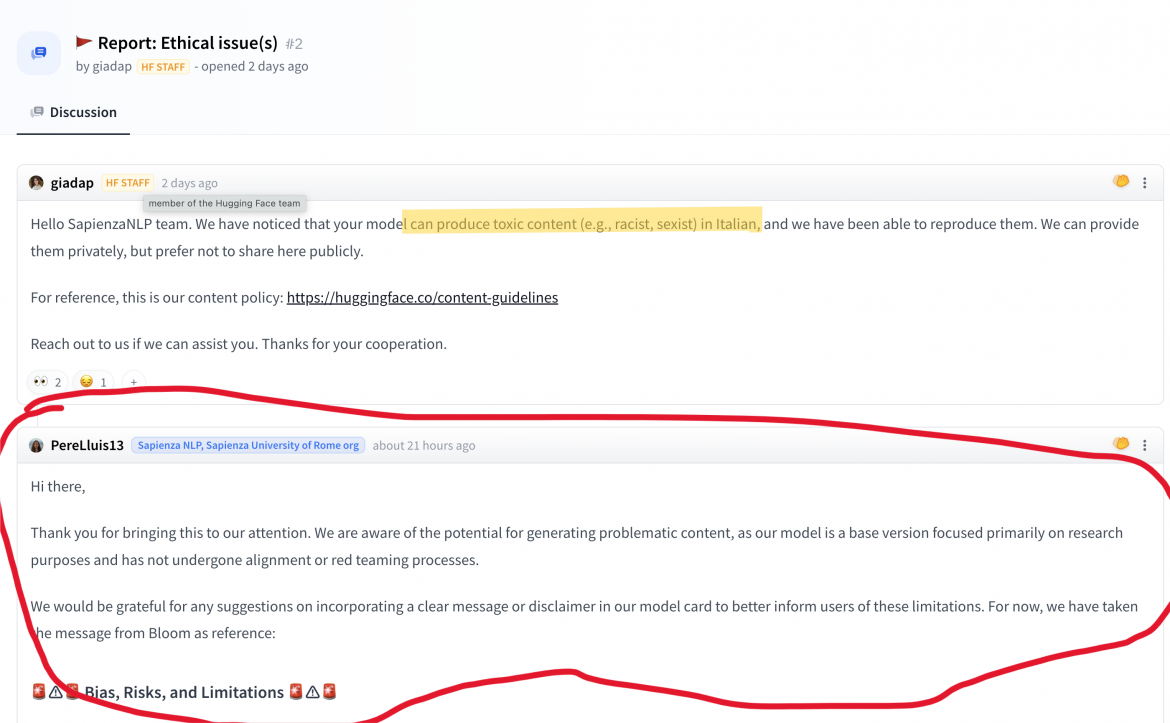
Il “disclaimer” del team romano parla chiaro: “is a pretrained base model and, therefore, has no moderation mechanisms”, ha il limite di essere rivolto agli addetti ai lavori. Troppo poco per i nostri tempi di ansia sull’intelligenza artificiale.
Lo scopo del team universitario non era certamente quello di fare un chatbot, bensì quello di produrre una base per sperimentazioni e raffinamenti. Ma vallo a spiegare.
Bisogna sapere che il comportamento “politicamente corretto” (talvolta anche pedante) dei modelli che vanno per la maggiore sono ottenuti “educando” il modello pre-addestrato, ottenuto dalla distillazione dei testi, con tanti esempi di buona condotta e con severa punizione delle intemperanze verbali.
Un lavoro lungo e costoso sia in termini di lavoro umano, sia in termini di risorse di calcolo. Per fare ChatGPT, dicono le cronache, OpenAI assoldò ai suoi tempi legioni di lavoratori nigeriani pagandoli due dollari l’ora.
La redazione consiglia:
ChatGpt, Antonio Casilli: Il lato oscuro dell’algoritmo è la forza lavoroUna strategia per ridurre questo sforzo potrebbe consistere nella selezione delle fonti testuali per il pre-addestramento (sembra che questa sia anche l’intenzione di iGenius). Ma questa si scontra col fatto che, per ottenere alla fine risultati apprezzabili, è necessario fornire alla macchina così tanti testi che la loro cernita potrebbe risultare problematica, specie se si tratta di una lingua diffusa ma non diffusissima come l’italiano, e specie se si vogliono tenere in conto anche le questioni di copyright.
La complessità morfologica della nostra lingua, poi, non aiuta: per come l’AI vede le parole (cioè del tutto a digiuno di qualsiasi grammatica), le nostre forme verbali piene di pronomi (dirglielo, mangiarselo) sono difficili da digerire.
Di fatto, il team di Sapienza ha usato per lo più testi provenienti dalla piattaforma di condivisione di testi docplayer.it il cui motto è: “Caricate tutto quello che volete!”. E gli utenti lo prendono alla lettera. Si tratta insomma di “junk text” affetto anche da problemi di copyright.
Era necessario attingere anche a quella fonte? Forse sì, se è vero quello che dicono le big-tech, e cioè che è praticamente impossibile ottenere un Large Language Model senza tiragli addosso tutto il testo che si ha sottomano. A rendere decenti questi generatori ci deve pensare, evidentemente, la costosa “high-school” dell’apprendimento per rinforzo e del raffinamento a-posteriori (fine-tuning).
La redazione consiglia:
MeMa, una creatura intelligente all’incrocio dei mondiDunque qual è la prospettiva dei modelli linguistici italianissimi? Se mettiamo da parte una certa retorica patriottarda che strizza l’occhio al sovranismo più velleitario, il tema può essere, all’atto pratico, ridimensionato. Oltre al fatto che GPT e Claude potrebbero passare indenni sotto le forche della Crusca, vi sono modelli multilinguistici aperti come LLama e Mistral che in italiano se la cavano mica male. Estenderli e raffinarli può essere (ed è) una valida alternativa a basso costo e a portata di mano.
Sul tema grava peraltro un problema di fondo, ben visibile anche nelle declaratorie che hanno accompagnato la presentazione del “Modello Italia”. Parliamo della circostanza tecnica per cui, in un modello linguistico, le competenze morfologiche, sintattiche, lessicali, semantiche e fattuali sono fuse in un unico gigantesco blocco di bit.
Dunque se da un testo vuoi prenderti la sintassi devi anche accettare il suo “senso comune” e, per converso, se vuoi includere solo testi italiani veritieri e leggiadri (e liberi da copyright) allora otterrai anche il loro stile.
La redazione consiglia:
E se ChatGpt fosse un autore del New York Times?Insomma, potremmo avere un modello linguistico basato solo su testi impeccabili sotto ogni profilo e liberamente disponibili in italiano, ma forse finirebbe parlare come Manzoni, il che sarebbe bellissimo ma certamente un po’ anacronistico.
I consigli di mema
Gli articoli dall'Archivio per approfondire questo argomento



