


Vediamo come funziona il data mining politico-elettorale di Cambridge Analytica.
D come data mining. Per Wikipedia il data mining «è l’insieme di tecniche e metodologie che hanno per oggetto l’estrazione di un’informazione o di una conoscenza a partire da grandi quantità di dati».
Il processo avviene attraverso metodi automatici o semi-automatici. E aggiunge che con data mining «si intende anche l’utilizzo scientifico, industriale o operativo di questa informazione».
Perciò grazie Wikipedia, e non dimenticate di fare una donazione all’enciclopedia libera che tutti usano senza dirlo per le sue belle e sintetiche definizioni.
Nell’epoca di Facebook e dei «Big Data», il data mining è cruciale per individuare la propensione all’acquisto dei consumatori, ma anche per definirne il profilo politico, sessuale, religioso. Perfino il rischio sanitario o creditizio.
I dati, provenienti dalle fonte più disparate, come l’uso di app, computer e smartphone, carta degli sconti, tessere elettroniche e per la pay-tv, vengono raccolti in grandi database e, incrociati fra di loro, possono essere usati per costruire profili singoli e aggregati, individuali e collettivi di consumatori, lavoratori o elettori.
Questi dati, shakerati con i metodi della statistica e delle scienze sociali grazie a sistemi automatizzati, definiscono la nostra «data-immagine». Che è il profilo digitale della nostra persona, quello che ci precede quando andiamo a chiedere un mutuo in banca o cerchiamo di contrattare con l’assicurazione.
Però mentre prima questi dati andavano raccolti e con fatica da fonti diverse, oggi basta usare quelli accumulati da social network come Facebook per fare una profilazione completa degli individui ed essere in grado di offrire al consumatore quello che è più propenso a desiderare.
Per capire come questo accade, la società Data X, di base a New York, ha creato un add-on, un’estensione per Mozilla Firefox o Chrome, che si chiama Data Selfie. Scaricata e installata sul nostro computer ci permette di vedere quanto tempo passiamo a leggere i post dei nostri amici, quanti like produciamo, quanti link clicchiamo e che cosa digitiamo o cancelliamo dai post di Facebook.
Dopo avere interagito un poco sulla piattaforma avremo un quadro preciso e dettagliato del tipo di dati che sono in possesso di Facebook e potremo capire perché sia al centro dello scandalo di Cambridge Analityca, accusata di aver contribuito a manipolare il voto della Brexit e quello per Trump proprio grazie a un uso spregiudicato dei dati degli utenti di Zuckerberg.
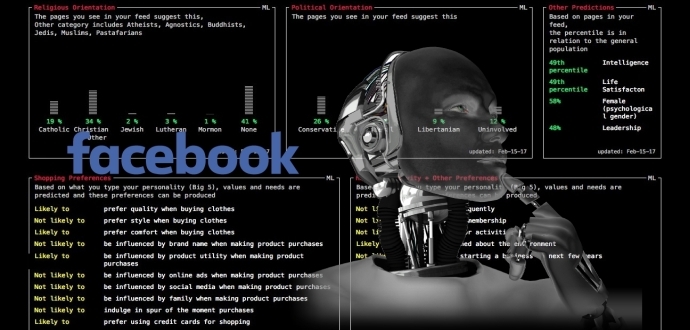
Ma Data Selfie fa di più: usando degli algoritmi matematici impilati in un software dall’Università di Cambridge è in grado di generare un profilo psicologico dettagliato dell’utente legato a età, genere, preferenze sessuali, intelligenza, ma anche soddisfazione per la vita, orientamento politico e religioso.
Per farlo usa anche alcuni strumenti di IBM Watson, l’intelligenza artificiale di IBM, che è in grado di identificare emozioni, propensioni sociali e stili di vita dei soggetti di cui elabora i dati.
È proprio quello che faceva Cambridge Analityca a giudicare dal rapporto creato da Michael Phillips, suo impiegato esperto di «Big Data»: con poche righe di codice reso pubblico sul sito GitHub, Phillips era in grado di geolocalizzare gli elettori e poi attraverso gli hashtag usati, i link cliccati e le conversazioni intrattenute, ricavarne il «sentiment», cioè l’inclinazione emotiva e cognitiva verso temi elettorali per poi cucirgli addosso un messaggio politico che “non erano in grado di rifiutare”.